Grundstruktur
Starten wir einfach mal auf der grünen Wiese. Gestartet wird mit einer leeren Visual Studio Projektmappe die auf deinem Rechner angelegt wird. Das darf auch schon ein leeres Git-Repository sein, die Struktur legst du selbst fest. Häufig wird der Quellcode in einen Unterordner „Code“ oder „Source“ strukturiert abgelegt. Also im Startfenster Neues Projekt erstellen auswählen, dann nach Leere per Suchfeld filtern und die leere Projektmappe erstellen. Es entsteht dann die .sln Datei und der versteckte .vs Ordner. Sollte die Struktur nicht stimmen, Visual Studio beenden, die beiden Dateien in den richtigen Ordner schieben und Visual Studio neu per sln-Datei öffnen.
In der leeren Projektmappe kannst du dir jetzt eine Struktur aufbauen. Diese Projektmappenordner werden per Rechteklick auf die Projektmappe > Hinzufügen > Neuer Projektmappenordner erstellt. Ich werde das nach unseren geplanten Einzelteilen strukturieren, deshalb habe ich einen Ordner für Server und dort drin für die Datenbank angelegt.
Im Database Ordner kommt jetzt das SQL-Server-Datenbankprojekt per Rechtsklick > Hinzufügen > Neues Projekt. Sofern SSDT ( SQL Server Data Tools) installiert sind, lässt sich der Projekttyp schnell rausfischen und erstellen. Namen angeben und ab dafür.
Damit haben wir ein wunderschönes leeres Projekt, dort wird jetzt etwas Struktur angelegt. Und zwar mehrere Ordner und Unterordner die schlussendlich die Struktur innerhalb des SQL-Servers abbilden. Der Exkurs, wie man weiß, was man da anlegen muss, kommt am Ende vom Artikel.
Etwas Sicherheit einziehen
OK, für die nächsten Schritte muss ich aber vorher ein paar Dinge erklären, ansonsten erschließt sich nicht wofür der Firlefanz gut ist. Der grundsätzliche Wunsch den wir haben wollen ist Funktionalität, Übersicht und Struktur sowie Sicherheit im Betrieb – also Zugriffsrechte steuern können. Wenn du schonmal mit SQL-Server zu tun hattest, z.B. administrativ oder rudimentär als Entwickler, dann sind dir „dbo“ und Aktionen wie Select auf Tabellen untergekommen. Und da kommen wir zur Historie des Produkts. Microsoft hat mit SQL-Server 2005 den Unterbau geändert und empfiehlt nicht mehr die Benutzung von dbo. Dbo ist kurz für Databaseowner und benennt das Standardschema der Datenbank. Das bedeutet, wir werden kein Element innerhalb dieses Schemas anlegen – die meisten Tutorials und Anleitungen machen das aber noch, obwohl Microsoft das nicht mehr empfiehlt. Deshalb hast du den Unterordner „Person“ angelegt. Die Daten die wir zu einer realen Person sammeln, sollen im Schema „Person“ angelegt werden, nicht dbo.
Das zweite wichtige Ding war ja die Sicherheit. Ein weit bekanntes Thema ist SQL Injection, also das ausführen von SQL Befehlen, die irreparablen Schaden an der Datenbank anrichten, in dem sie zum Beispiel ganze Tabellen löschen. Das werden wir nicht zulassen, denn wir werden dem späteren Web-API-Nutzer ausschließlich Zugriff auf gespeicherte Prozeduren (Stored Procedures) gewähren. Auch könnten wir dank des Schemas komplett änderbare Bereiche definieren: „Du darfst Personal, aber nicht Vertrieb.“ Es gibt kein direktes Select, Insert, Update oder Delete an die Hand.
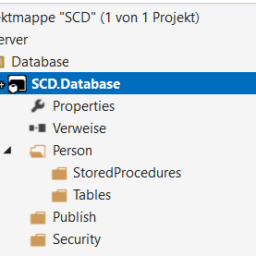
Und deshalb ist der Security Ordner da, dort drin startet die Reise. Du legst jetzt nämlich nacheinander mehrere Elemente in diesem Ordner an. Das passiert immer über Rechtsklick > Hinzufügen > Neues Element.
- Zuerst kommt ein Datenbankbenutzer, das wird der Besitzer des Schemas ohne Login. Microsoft sagt: Abweichender Nutzer der nur ein oder mehrere Schemata besitzt, kein Login, sonst keine Funktion.
- Hinzufügen des Schemas.
- Hinzufügen einer Datenbankrolle. Über diese steuern wir wer und vor allem was der in diesem Bereich der Datenbank anstellen darf.
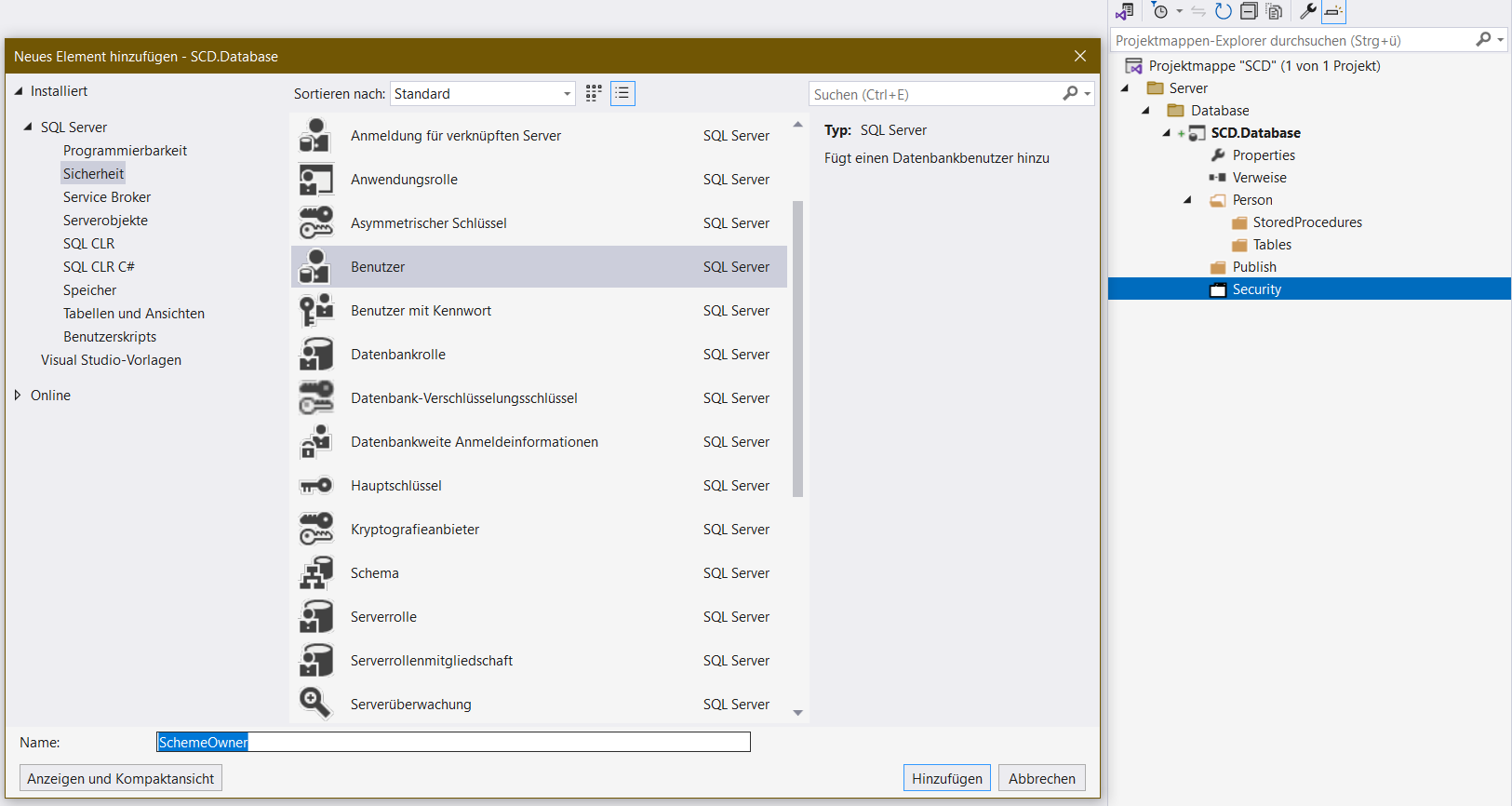
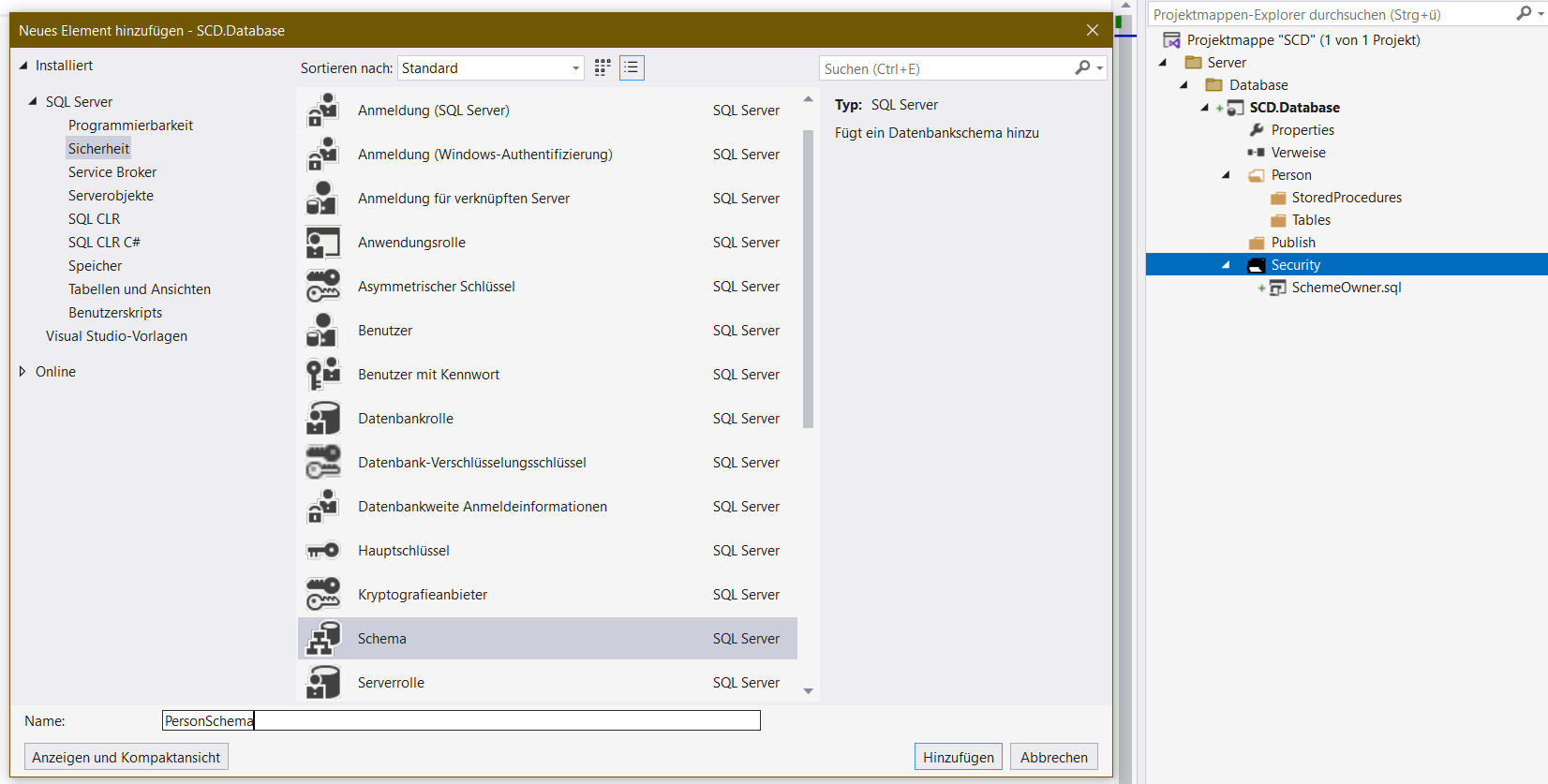
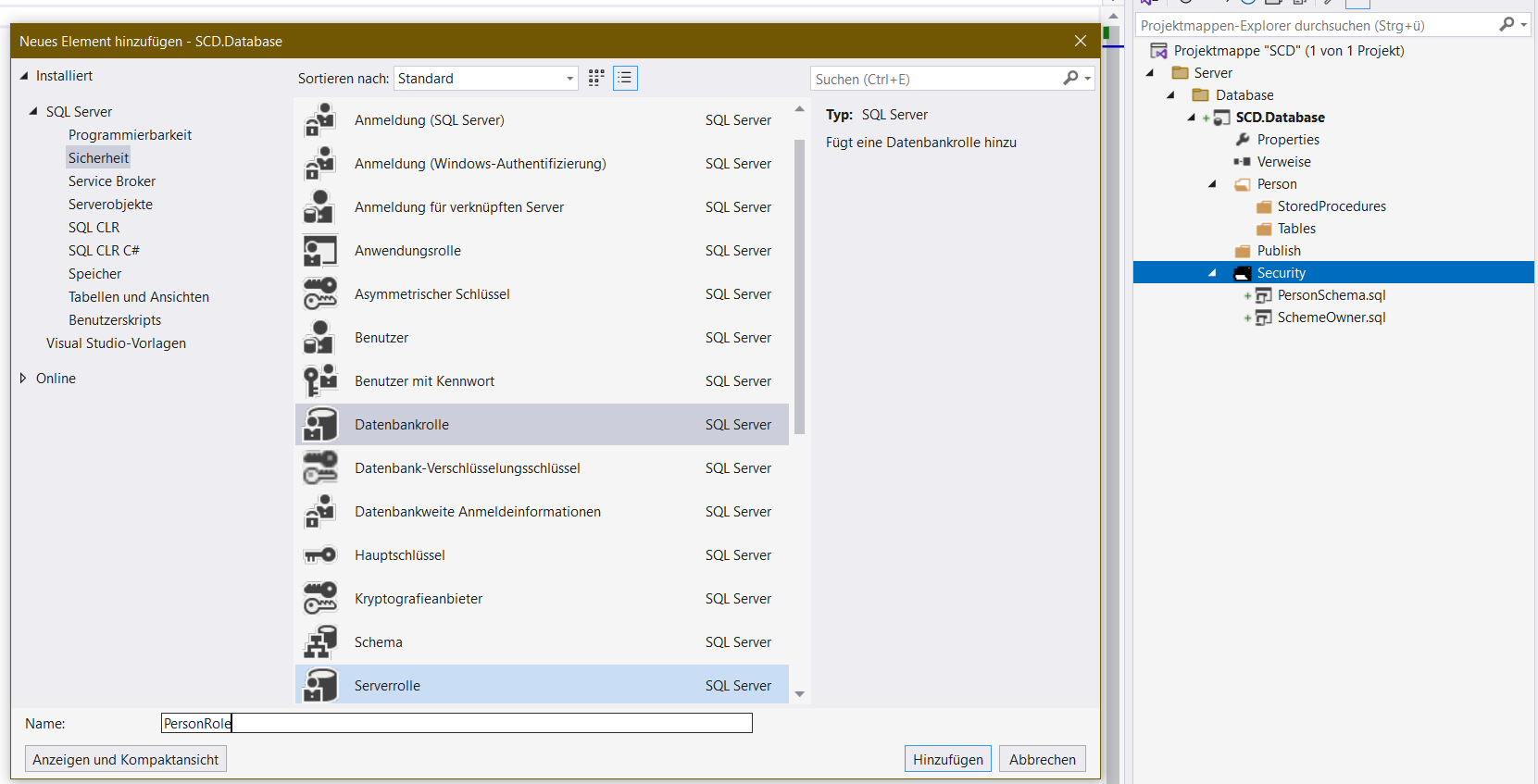
In der SchemeOwner.sql werden dir mehrere Zeilen eingefügt. Brauchst du alles nicht, du löscht das Unnötige und reduzierst das auf nur:
CREATE USER [SchemeOwner] WITHOUT LOGIN
In der PersonSchema.sql ist auch viel drin, das kann auch reduziert werden. Zuerst machst du nur das reine Schema. Es steht da also die eine Zeile drin:
CREATE SCHEMA [Person] Authorization SchemeOwner
Ich habe auch den Namen des Schemas korrigiert. Der Name der *.sql Datei selbst und das was dort drin passiert kann abweichen, empfiehlt sich auch für die Übersicht. Unser Schema soll ja in der Datenbank selbst „Person“ heißen und nicht „PersonSchema“. Heißt, erstelle das Schema, der Besitzer wird unser SchemeOwner. Der muss halt vorher angelegt werden, sonst kringelt dir das Visual Studio rot an „find ich nicht“.
Als drittes jetzt die Datenbankrolle. Da steht noch weniger drin, nämlich nur:
CREATE ROLE [PersonRole]
So. Und jetzt, wo du die Rolle hast, kannst du nochmal die PersonSchema.sql Datei öffnen und definieren was diese Benutzerrolle denn können soll. Du erweiterst also den Inhalt auf:
CREATE SCHEMA [Person] Authorization SchemeOwner Go Grant Execute On Schema::Person To PersonRole
Und damit haben wir´s dann. Das „Go“ muss im SQL-Server hier und da gesetzt werden, es führt den Befehl davor aus. Du kannst erst Rechte auf etwas setzen wenn es da ist. Also: erstelle das Schema, und dann gib der Rolle das Execute Recht auf das gesamte Schema. Bedeutet, jegliche Stored Procedure die wir im Laufe der Zeit in diesem Schema anlegen, darf von Nutzern in der Datenbankrolle PersonRole ausgeführt werden – sonst nix. 🙂
Hinweis: Diese drei „Typen“ müssen wie gezeigt in das VS Projekt integriert werden. Du kannst nicht einfach eine leere .sql Datei erstellen und das reinkopieren. Visual Studio erkennt dann nicht, dass da ein Benutzer, ein Schema und eine Rolle angelegt wird. Das verknüpft sich das hinter dem Vorhang um alles richtig anzulegen und auch zu wissen das es da ist.
Erste Datentabelle
Jetzt, da wir ja unser Schema haben, können wir auch mal eine erste Tabelle anlegen. Klappt per Rechtsklick auf den Ordner Tables > Hinzufügen > Tabelle. Dann vergibst du den Namen „Person“ und lässt das Ganze erstellen. Im Ergebnis bekommst du eine leere Tabellenstruktur mit einer Id Spalte.
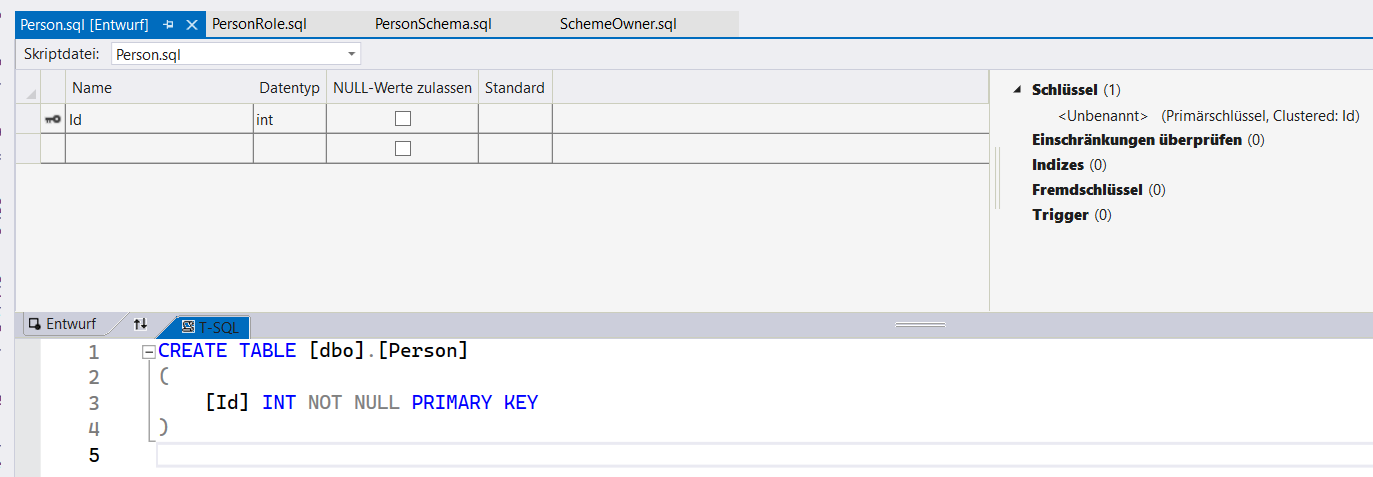
Im Grunde ist das nichts anderes als ein visueller Designer für SQL-Tabellen. Du kannst gemischt hantieren und Spalten im oberen Bereich wie in Excel oder dem SQL Server Management Studio anlegen oder direkt unten als SQL Syntax. Auf jeden Fall musst du das Schema ändern, da steht nämlich das falsche dbo. Das Identity(1,1) setze ich auch immer direkt in der Syntax. Im Ergebnis entsteht in unserem Bastelprojekt dann das:
CREATE TABLE [Person].[Person]
(
[Id] INT NOT NULL PRIMARY KEY IDENTITY(1,1),
[FirstName] NVARCHAR(100) NOT NULL,
[LastName] NVARCHAR(100) NOT NULL
)OK, cool. eine Tabelle haben wir. Dann jetzt die Stored Procedures. Also Rechtsklick auf den Ordner > Hinzufügen > Gespeicherte Prozedur > Name vergeben „Person_GetAll“. Du erhältst eine Datei mit:
CREATE PROCEDURE [dbo].[Person_GetAll] @param1 int = 0, @param2 int AS SELECT @param1, @param2 RETURN 0
Erster Blick, Schema falsch und irgendwelche Twitternamen – naja, fast. Sind halt Parameter, die der Prozedur übergeben werden können. Korrigieren wir das.
- Schema von dbo in Person ändern
- Die @ Parameter raus
- Die Prozedur startet mit Begin nach dem As und mit
set nocount on;werden nicht die betroffenen Zeilen mit ausgegeben. (Kann der SQL für sich behalten 🙂 ) - das Select Statement eintippern – Feststellung: Intelli Sence wird dir wie auch im C# Code Vorschläge zu Schema und Tabellennamen machen wenn du die Anfangsbuchstaben tippst
- alles mit End abschließen
CREATE PROCEDURE [Person].[Person_GetAll] As Begin Set nocount on; Select * From Person.Person End
Aber Tobi, du musst doch „usp_“ als Prefix im Namen der Prozedur schreiben!!!! :-O
X auf Y im Netz
Ja, sieht man öfter. Mach ich trotzdem nicht:
- Die Prozeduren liegen alle im selben Ordner im SQL-Server, die systemeigenen in einem anderen Unterordner mit ihrem typischen sp_ Prefix. Verwechslung ist nahezu unmöglich was systemeigenen und was von uns angelegt wurde.
- Der Programmierer wird ausschließlich mit den Prozeduren arbeiten, niemals mit Tabellen. Das ist also viel übersichtlicher und im C# macht ihr doch auch keine ungarische Notation mehr. Kannste also auch hier lassen.
Deplooooy
Nix mit Pipeline, wir machen das hier auf unserer kleinen Farm direkt. Und zwar zuerst auf localhost, bringt das Visual Studio ja mit sofern es angehakt wurde. Unterstelle ich mal, SSDT sind ja auch vorhanden. Sonst wären wir nicht hier. 😉
Und zwar, indem du per Rechtsklick > Veröffentlichen auf das Projekt das passende Fenster aufrufst. In diesem Fenster kannst du oben direkt den Pfad zum Server wählen, da nimmst du localhost. Dann vergibst du mittig im Fenster noch den Datenbanknamen und abschließend gibt es unten Profil speichern unter. Und du speicherst es im Projekt in den Publish Ordner. Das müsste dann auch in der Projektmappe in genau diesem Unterordner gelistet werden, du kannst also direkt rechts unten auf Veröffentlichen klicken.
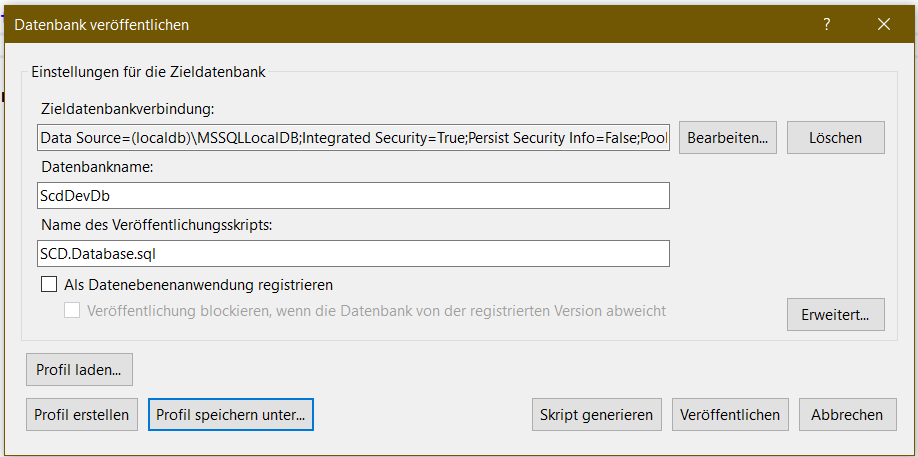
Und dann rödelt es kurz uuuuuund du bekommst eine Fehlermeldung:

Tja, dumm gelaufen. Aber behebbar. Rechtsklick auf den Projektnamen SCD.Database > ganz unten Eigenschaften. Da steht als Zielplattform Server 2022 oder Azure. Nun, mit dem hier grad aktuellen Visual Studio 2022 v17.8 kommt aber der SQL 2019 mit, heißt, da muss also 2019 als Ziel eingestellt werden.
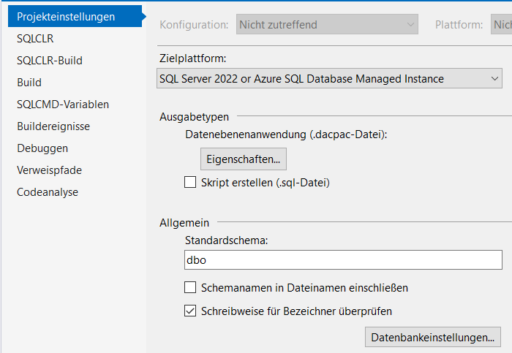
Und Profitipp: Schau mal weiter unten, da steht „Standardschema“. Wenn du ganz viele Dinge eines Schemas anlegst, lohnt sich das umstellen für diese Zeit. 😉
Gut, speichern der Eigenschaften, dann Doppelklick auf die publish.xml und nochmal veröffentlichen. Und dann sollte es flutschen.
Sollten trotzdem Fehler auftauchen und sich das Publish Fenster gar nicht erst öffnen, dann ruhig mal das Projekt erstellen lassen. Gerne hat man mal ein Begin oder End oder ein ; vergessen. Diese Art Compilerschutz geht hier also auch.
Checken was angekommen ist
Dann ist also die Datenbank jetzt ausgerollt. Schauen wir doch mal rein – und zwar mit dem Microsoft SQL Server Management Studio (SSMS). Verbindung auf (localdb)\mssqllocaldb aufbauen mit dem lokalen (Active Directory) Benutzerkonto.
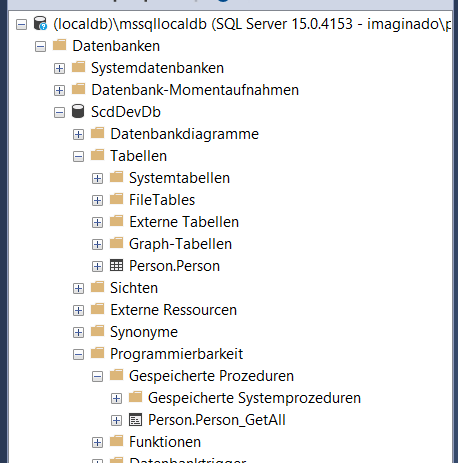
Es sollte sich alles wiederfinden lassen. Unsere Tabelle wird bei den Tabellen gelistet, die gespeicherte Prozedur versteckt sich unter Programmierbarkeit. Unter dem Reiter Sicherheit > Benutzer, Rollen und Schema findest du den Rest der angelegten Elemente. Klappt also mit dem Deployment.
Per Rechtsklick auf die Person.Person Tabelle und Oberste 200 Zeilen bearbeiten werfen wir mal ein paar Daten in die Tabelle. Du brauchst logischerweise nur Vor- und Nachname ausfüllen, Id kommt automatisch. Wenn du 2-3 Personen eingetragen hast findest du oben in der Befehlsleiste Neue Abfrage. Wenn du dort den passenden SQL Befehl eintippst, sollten alle Elemente in der Tabelle mit unserer gespeicherten Prozedur abgerufen werden.
use ScdDevDb go exec Person.Person_GetAll
Unten im Fenster werden dann die Elemente zurückgegeben. Das SQL Kommando wählt erst die gewünschte Datenbank aus und per exec wird die Prozedur aufgerufen.
Restliche Prozeduren hinzufügen
SSMS kann offen bleiben, zurück ins Visual Studio. Ergänzen wir mal die restlichen Prozeduren die wir voraussichtlich brauchen werden. Also per Rechtsklick auf StoredProcedures > Hinzufügen > Gespeicherte Prozedur alle hinzufügen. Und immer auf das Schema aufpassen. Zuerst ein Element per Id abfragen:
CREATE PROCEDURE [Person].[Person_GetById] @Id int As Begin Set nocount on; Select * From Person.Person Where Id = @Id End
Person_Set ist bisschen spannender. Mittlerweile trenne ich nicht mehr Create und Update. Der SQL Server kann anhand der übermittelten Werte selbstständig entscheiden was er machen muss. Der Result Parameter ist momentan etwas verwirrend, wird uns später aber nützlich sein, damit die Web API, weiß was die Datenbank angestellt hat.
CREATE PROCEDURE [Person].[Person_Set] @Id int, @FirstName nvarchar(100), @LastName nvarchar(100), @Result int output As Begin Set nocount on; If Exists(Select Id From Person.Person Where Id = @Id) Begin Update Person.Person Set FirstName = @FirstName, LastName = @LastName Where Id = @Id Set @Result = -204 End Else Begin Insert Into Person.Person(FirstName, LastName) Values(@FirstName, @LastName) Set @Result = SCOPE_IDENTITY() End Select @Result End
Person_Delete ist ähnlich aufgebaut. SQL Server soll selber checken ob die Person existiert, dann löschen, sonst anderen Statuscode zurückgeben. Vielleicht erahnt man es ja schon, es sind negative HTTP Statuscodes die ich da missbrauche. De facto werden die Ids der Tabelle immer positiv sein wenn sie durch Set erzeugt werden. Also ist alles was negativ ist kein Create/Insert gewesen und ich kann das in der API auswerten.
CREATE PROCEDURE [Person].[Person_Delete] @Id int, @Result int output As Begin Set nocount on; If Exists(Select Id From Person.Person Where Id = @Id) Begin Delete From Person.Person Where Id = @Id Set @Result = -204 End Else Begin Set @Result = -404 End Select @Result End
Gut gut. Doppelklick auf die publish.xml und nochmal an die Datenbank deploooyen. Und zurück in SSMS, die neuen Prozeduren versuchen wir doch gleich mal zu benutzen. Erstmal mit einem Set. Wenn irgendwann später eine neue Person angelegt werden soll, dann wird die schlicht mit der Id = 0 ankommen, halt integer Standardwert. Dann der eigentliche Vor- und Nachname, und am Ende das Result. Ich hatte vorher 3 Namen in der Tabelle, ich bekomme also jetzt eine 4 im Ergebnisfenster zurück.
use ScdDevDb go exec Person.Person_Set 0, 'Pit', 'Possum', 0
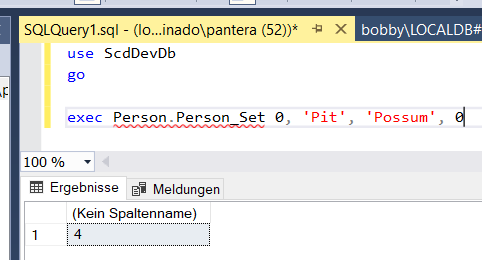
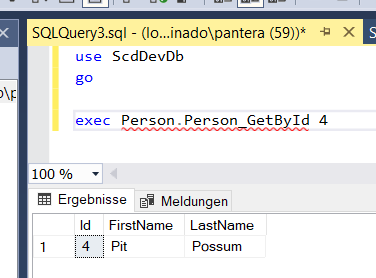
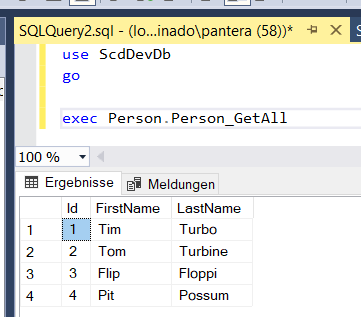
Stimmt alles soweit. Das bedeutet, wenn die Set Methode jetzt mit einer bekannten Id und Daten gefüttert wird, dann sollte ja das Update getriggert werden und -204 zurückkommen. Ausprobieren und Ergebnisfenster checken. Klappt zumindest bei mir, die beiden Get Prozeduren stimmen dem zu. 😛
use ScdDevDb go exec Person.Person_Set 4, 'Pete', 'Possum', 0
Die Delete Prozedur sollte ähnlich klappen. Wird eine unbekannte Id reingekippt, sollte ein -404 kommen. Ansonsten ein -204, dass es erfolgreich geklappt hat.
use ScdDevDb go exec Person.Person_Delete 7, 0
OK, dann haben wir unser Datenbankprojekt ja grundsätzlich zusammengestrickt und können jetzt die Datenbank als Code verwalten und auf einen Server ausrollen. Die Rechte für die API kommen später wenn wir soweit sind, bleibt noch eine Sache vom Anfang übrig. Woher wusste der Kerl, welche Ordner er anlegen muss.
Ursprung der Ordner ergründen
Dafür lege ich mal parallel ein neues leeres SQL Projekt im Visual Studio an. Das fliegt danach wieder weg. Wenn das erzeugt wurde, machst du direkt mal einen Rechtsklick drauf und wählst Schemavergleich. In dem sich öffnen Tab nimmst du das linke DropDown und klickst Quelle auswählen, dort dann Datenbank und hangelst dich zu deiner vorhin ausgerollten Datenbank auf localhost durch. Im rechten Dropdown ähnlich, allerdings wird das Ziel das eben erstellte Projekt. Und dann klickt du links oben auf Vergleichen und wartest kurz.

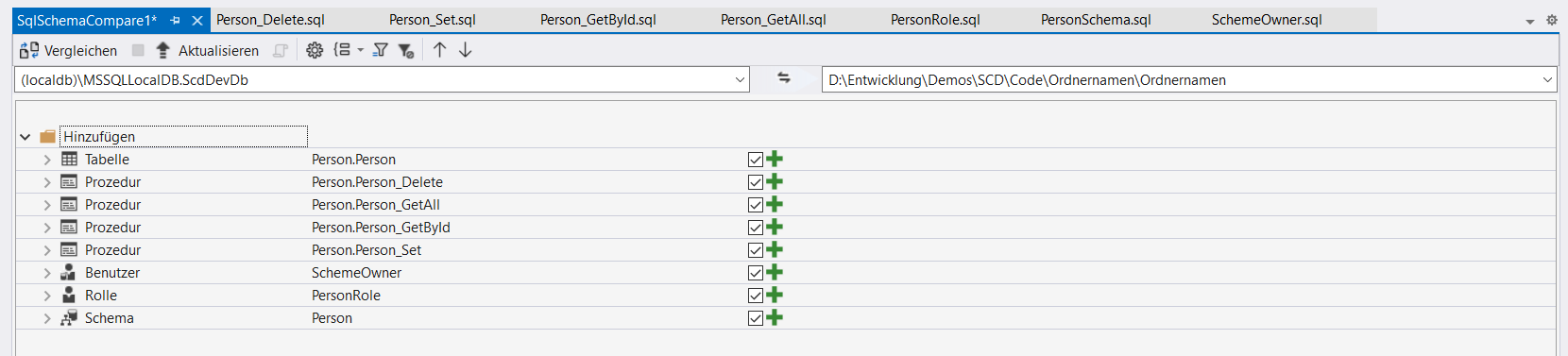
Jetzt siehst du was es in der Datenbank gibt und was im Projekt fehlt und hinzugefügt werden könnte. Der Aktualisieren Button ist jetzt auch klickbar, das machst du auch direkt. Die Nachfrage wird bejaht, und zack wird das Schema vom Server gezogen und in das Projekt integriert. Und tadaaaa da sind wieder unsere Ordner.
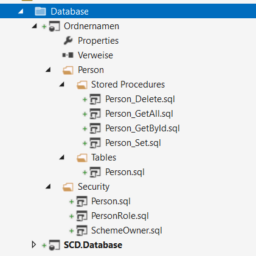
Publish fehlt, logo. Das ist ja nicht in der Datenbank. Bedeutet, wenn du vor einer unbekannten Datenbank sitzt oder nicht weißt wo was hin müsste, zB bei der Microsoft eigenen AdventureWorks Datenbank die Microsoft ja in seinen Tutorials verwendet, dann kannst du dir das damit einfach in dein Projekt ziehen. Theoretisch könnte man den Abgleich auch machen wenn mehrere Personen an der Datenbank entwickeln, da ist es aber besser sich abzusprechen und das per git zu aktualisieren, damit die Branches nicht Änderungen inne haben, die gar nichts mit dem Branch zu tun haben.