High Availability Lösungen sind nette Geschichten, versprechen sie doch unterbrechungsfreien Betrieb im Fehlerfall. Ganz so romantisch ist es dann doch nicht, aber nahe dürfte es schon kommen. Synology bietet für seine NAS mit wenigstens zwei Netzwerkports auch sowas an.
Allerdings bedeutet jedes Cluster neue Zwänge und Mehraufwände. Im Falle eines NAS müssen beide Geräte identisch bestückt sein und Updates müssen schrittweise und geplant eingespielt werden, da ja immer ein Gerät für ein paar Minuten „weg“ ist. Wenn man jetzt keine horrenden Summen in Storage Systeme und Cluster stecken möchte, aber doch eine gewisse Ausfallsicherheit gewährleisten will, könnte man ja ein Medium Availability „Cluster“ bauen. 😋 Am Schaubildchen zeigt sich das einfacher:
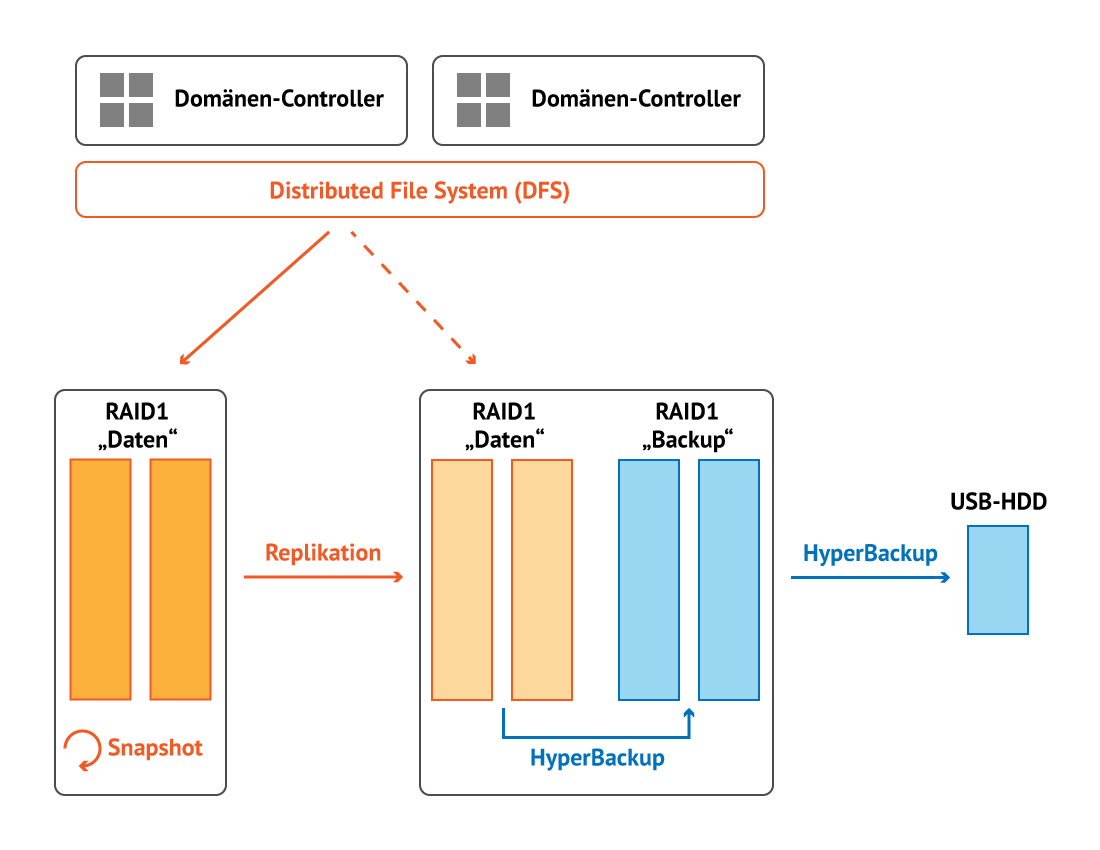
- Grundlage sind zwei NAS die auch unterschiedlich viele Laufwerkschächte haben können. Sie müssen aber BTRFS unterstützen.
- Auf dem „Haupt“NAS werden die aktiven Daten abgelegt, es wird Snapshot & Replication installiert. Die lokalen Snapshots werden konfiguriert, z.B. stündlich.
- Auf dem zweiten NAS werden wenigstens 2 Volumes angelegt. Auf einem wird die Replikation der Daten abgelegt. Auf dem zweiten Volume schreibt HyperBackup z.B. jeden Abend eine Sicherung der replizierten Daten. Die Replikation zwischen den NAS kann im Prinzip auch beliebig oft geschehen, es empfiehlt sich aber identisch zur lokalen Replikation auf dem Haupt-NAS zu arbeiten.
- Hyper Backup kann zusätzlich alle Daten auf eine externe Platte spiegeln.
- In der Windows Domäne wird DFS als Bereitstellung für die Netzlaufwerke genutzt. Die einzelnen Ordner im DFS verweisen nur auf das Haupt-NAS.
So lässt sich beispielsweise mit verhältnismäßig kleinen DS218 und DS418 ein recht robustes System für ein kleines Büro umsetzen.
- Die Daten sind an mehreren Orten und womöglich Brandabschnitten vorhanden.
- Es gibt eine Art Backup-Konzept, schonmal mehr als nix.
- Es können SSD im Haupt-NAS mit HDDs im Zweit-NAS kombiniert werden, das geht bei SHA wohl nicht.
- Auch können unterschiedliche Geräte kombiniert werden, das geht bei SHA ebenfalls nicht. Wachstum oder Änderungen passieren aber in jedem Unternehmen.
- Das Backup-Volume könnte auch für andere Sicherungen genutzt werden, die von Veeam zum Beispiel.
- Je nachdem welches NAS verwendet wird, können 256 bis 1024 Snapshots auf beiden System vorgehalten werden. Das reicht häufig für versehentliches Löschen oder Verändern der Daten.
Natürlich hat aber auch dieses System wie jedes andere auch seine Grenzen. Die wichtigste Einschränkung ist: irgendjemand muss im Fehlerfall aktiv werden. Das ist aber kein Hexenwerk und lässt sich als Wissen schulen.
Haupt-NAS fällt aus
RAID ist zerstört oder das Gerät selbst fällt aus.
1. Die Replikationsverbindung muss aufgelöst werden. Sobald das geschehen ist, kann schreibend auf dem zweiten NAS gearbeitet werden.
2. Im DFS wird ein zweites Ordnerziel auf das Zweit-NAS angelegt, das erste Ziel wird danach entfernt.
3. Der Cache/Verlauf muss vom DFS-Ordner gelöscht werden, danach sind sofort die neuen Ziele aktiv.
DFS bietet in Kombination mit den beiden NAS eine sehr einfache Methode um Netzlaufwerke schnell umzuschalten. Würde man stattdessen Netzlaufwerke per GPO umschalten müssen, würde das viel länger dauern. So lässt sich die Aktion in 5-10 min umsetzen und wenn die Replikation stündlich läuft, ist auch kein Weltuntergang zu erwarten.
Der Rückweg ist leider etwas anstrengender. Im Prinzip muss man die Daten 1x zurück replizieren, dann im DFS zurück auf das Haupt-NAS schalten und dann die Replikation neu aufbauen. Damit verliert man leider die Snapshots.
Alternativ kann man das Zweit-NAS zum neuen Haupt-NAS erklären und das eh neu gekaufte Gerät wird das neue Replikationsziel. Dann muss nur das HyperBackup umziehen.
Zweit-NAS fällt aus.
Gerät kaputt, oder eins der RAID1 zerstört. Eigentlich passiert gar nichts. Ja, die Replikation wird scheitern. Die deaktiviert man dann. Wenn das Backup-Volume ausfällt könnte man direkt auf die externe HDD schreiben. Oder man hängt die externe HDD direkt an das Haupt-NAS und sichert dort erstmal lokal.
Wenn das Problem behoben wurde, baut man den ausgefallenen Teil wieder in das System ein und reaktiviert alle Komponenten.